


با سلام و درود چند وقتیست که درگیر مباحث Optimization در Django بالاخص سمت DB و ORM بودم که قدم اول آشنایی کامل با Query و QuerySet در جنگو هست، به همین دلیل تصمیم گرفتم در این مورد یه آموزش جامع و کامل قرار بدم و به توضیحا و معرفی کامل کوئری و کويری ست ها در جنگو بپردازم.
ابتدا مراجع اصلی این مجموعه آموزش رو معرفی کنم خدمتتون:
- مرجع اصلی و اول خود اسناد جنگو هستند:
- مرجع دوم کتاب : Two Scoops of Django 3.x
مقدمه
خب با کمترین مقدمه ممکن بریم سر اصل مطلب که Django با استفاده از Object-Relational Modelیا ORM اقدام به ساخت و تهیه یک سری شورتکات های قدرتمند و پر استفاده برای ما می کند. ORM همانند همگی ORMها داده ها را از type های متفاوت گرفته و به objectهایی که بتوانند در پایگاه داده های پشتیبانی شده استفاده شوند، تبدیل می کند. و سپس یک سری متد برای تعامل با این objectها برای ما فراهم می کند.
فرضیات آموزش
فرض اول ما این هست که شما با مباحث مقدماتی و Model ها در جنگو آشنایی دارید و سریع میریم سراغ فرضیاتی ازچند modelکه در ادامه مثال هایمان را با آنها پیش می رویم (یک اپلیکیشن بلاگ):
from django.db import models
class Blog(models.Model):
name = models.CharField(max_length=100)
tagline = models.TextField()
def __str__(self):
return self.name
class Author(models.Model):
name = models.CharField(max_length=200)
email = models.EmailField()
def __str__(self):
return self.name
class Entry(models.Model):
blog = models.ForeignKey(Blog, on_delete=models.CASCADE)
headline = models.CharField(max_length=255)
body_text = models.TextField()
pub_date = models.DateField()
mod_date = models.DateField()
authors = models.ManyToManyField(Author)
number_of_comments = models.IntegerField()
number_of_pingbacks = models.IntegerField()
rating = models.IntegerField()
def __str__(self):
return self.headlineساخت یک object از روی model و ذخیره آن در DB : آشنایی با متدهای save و create
برای اینکار به مثال زیر توجه کنید:
>>> from blog.models import Blog >>> b = Blog(name='Beatles Blog', tagline='All the latest Beatles news.') >>> b.save()
کد بالا در پس زمینه یک INSERT SQL انجام می دهد. توجه داشته باشید جنگو تا زمانی که save را فراخوانی نکنید، هیچ ارتباطی با DATABASE ندارد.
برای ایجاد و ذخیره کردن Objectبه صورت همزمان باید از create() استفاده کرد. جفت کد های زیر برابر هستند
p = Person(first_name="Bruce", last_name="Springsteen") p.save(force_insert=True)
p = Person.objects.create(first_name="Bruce", last_name="Springsteen")
پارامتر force_insert که آورده شده چیز خاصی نیست و وظیفه اش این هست که اطمینان حاصل کنده Objectساخته می شود. برای مواردی که از مدل شما از manual primary key value استفاده بکند. مقداری که دارید میدید در DB وجود داشته باشه و PK ارسالی uniqueنباشد متد create با مشکل روبرو شده و یک IntegrityError می دهد، چرا که PKباید حتما منحصربفرد باشد.
ذخیره تغییرات روی Objectمورد نظر
برای ذخیره تغییرات روی object که قبلا در db بوده، باید از save استفاده کرد.
>>> b5.name = 'New name' >>> b5.save()
کد بالا، یک UPDATE SQL انجام می دهد. جنگو تا زمانی که save را فراخوانی نکنید، کاری به DBنداشته و آن را لمس نخواهد کرد.
جنگو چطور UPDATE را در مقایل INSERT تشخیص می دهد؟
حتما دقت کردید که object های جنگو برای ساخت و ایجاد هردو از save استفاده می کنند. جنگو با توجه به نیاز، عمل UPDATE یا INSERT را انجام می دهد. مخصوصا زمانی که شما save را فراخوانی می کنید و شناسه PK از Object به صورت پیشفرض (default) تعریف نشده باشد، جنگو الگوریتم زیر را پیش می رود:
- اگر شناسه PK از Object مقداری گرفته باشد که منتج به TRUE باشد (مقداری بغیر از NONE یا یک string خالی )، جنگو یک UPDATE انجام می دهد.
- اگر شناسه PK از Object تنظیم نشده باشد یا UPDATE چیزی را برزورسانی نکند (اگر PK مقداری گرفته باشد که object ای متناظر با آن در DB نداشته باشیم) ، جنگو یک INSERT انجام می دهد.
اگر شناسه PK از object به صورت defaultتعریف شده باشد، سپس جنگو اگر یک instance از مدل وجود داشته باشد و PKآن برابر با مقداری که در DBاست تنظیم شده باشد، جنگو UPDATE را انجام می دهد. در غیر این صورت INSERT انجام می دهد.
اصرار به INSERT یا UPDATE :
در مواردی نایاب، نیاز هست که متد save رو اجبار کنید تا عمل مورد نظر شما را انجام دهد، برای این منظور می توانید ا زدو پارامتر force_insert=True یا force_update=True برای save استفاده کنید. (استفاده همزمان از این دو پارامتر منجر به ارور می شود)
ذخیره کردن فیلد های ForeignKey و ManyToManyField
ManyToManyField بروزرسانی فیلد ForeignKey دقیقا مشابه با روش save کردن یک فیلد معمولی می باشد.
مثال زیر ، مدخلی که کلید اصلی آن ۱ است را گرفته و بلاگ آن را برابر با بلاگی می گذارد که نام آن بلاگ “Cheddar Talk” باشد.
>>> from blog.models import Blog, Entry >>> entry = Entry.objects.get(pk=1) >>> cheese_blog = Blog.objects.get(name="Cheddar Talk") >>> entry.blog = cheese_blog >>> entry.save()
بروزرسانی فیلد ManyToManyField یه مقدار متفاوت می باشد، استفاده از متد add() روی فیلد جهت افزودن یک رکورد به آن ارتباط (relation). در مثال زیر یک نمونه از Author را به entry objectاضافه می کنیم.
>>> from blog.models import Author >>> joe = Author.objects.create(name="Joe") >>> entry.authors.add(joe)
برای افزودن چند رکورد به ManyToManyField ، چند آرگومان به add() دهید :
>>> john = Author.objects.create(name="John") >>> paul = Author.objects.create(name="Paul") >>> george = Author.objects.create(name="George") >>> ringo = Author.objects.create(name="Ringo") >>> entry.authors.add(john, paul, george, ringo)
استخراج Objectها :
برای استخراج Object ها باید یک QuerySet بسازید . QuerySet مجموعه ای از Object ها را از پایگاه داده به شما بر می گرداند. می تواند صفر، یک یا چند فیلتر هم داشته باشد. FIlter ها نتایج کوئری ها را متناسب با پارامترهای ورودی که می گیرند، لاغر تر می کنند. در SQL یک QuerySet برابر با SELECT می باشد.و Filterبرابر با WHERE یا LIMIT می باشد.
شما QuerySet را با استفاده از Manager های مدل میگیرد. هر مدل حداقل یک Manager دارد و به صورت پیش فرض objects نامیده می شود.
>>> Blog.objects
<django.db.models.manager.Manager object at ...>
>>> b = Blog(name='Foo', tagline='Bar')
>>> b.objects
Traceback:
...
AttributeError: "Manager isn't accessible via Blog instances."Manager ها فقط از طریق کلاسهای مدل در دسترس هستند و از طریق instance های مدل در دسترس نیستند (برای اعمال تفکیک بین عملیات «در صطح جدول» و عملیات «در سطح ردیف» )
گرفتن تمامی objectها :
آسانترین راه برای گرفتن object های یک table، گرفتن تمامی آنها می باشد. برای اینکار از متد all()از Managerاستفاده کنید:
>>> all_entries = Entry.objects.all()
روش های ارزیابی QuerySet :
- تکرار – iteration : یک کوئری ست به صورت تکرار پذیر می باشد (iterable)
for e in Entry.objects.all():
print(e.headline)نکته: اگر تنها کاری که میخواهید انجام دهید این است که ببینید آیا حداقل یک نتیجه وجود دارد، کار فوق را انجام ندهید و بجاش از exists() استفاده کنید.
- برش دادن – Slicing: می توان با استفاده از سینتکس برش دادن آرایه پایتون (Python’s array-slicing syntax)، یک کوئری ست را برش داد.
برش دادن یک QuerySet ارزیابی نشده معمولاً یک مورد ارزیابی نشده دیگر را برمی گرداند منتهی جنگو کوئری دیتابیس را اگر پارامتر step از سینتکس برش را تنظیم کرده باشید انجام می دهد وی ک لیست برمیگرداند.
- Pickling/Caching : در بخش بعدی به صورت مفصل بهش میپردازیم.
- repr() : یک کوئری ست زمانی که repr را روی آن فراخوانی کنید، ارزیابی می شود. این برای راحتی مفسر تعاملی پایتون است. بنابریان می توانید به هنگامی که از API به طور تعاملی استفاده می کنید، بلافاصله نتایج خود را مشاهده کنید.
- len() : یک QuerySet زمانی که repr را روی آن فراخوانی می کنید، ارزیابی می شود. همان طور که احتمالش میره شما انتظار دارید طول بیست نتایج را به شما برگرداند.
توجه: اگر شما فقط احتیاج دارید که تعداد رکورد های داخل مجموعه را بدانید (نیازی به objectهای حقیقی ندارید)، کارایی استفاده از count در سطح دیتابیس بیشتر می باشد، استفاده از SELECT COUNT(*) . جنگو دقیقا به همین دلیل متد count() را ارائه می دهد.
- list(). اجبار به ارزیابیQuerySet با فراخوانی list() روی آن انجام می شود. برای مثال:
entry_list = list(Entry.objects.all())
- bool().جهت تست کردن یک QuerySet با محتوای boolean از bool یا and یا ifاستفاده می شود. اگر حداقل یک نتیجه وجود داشته باشد، QuerySet درست/Trueمی باشد و در غیر این صورت False می باشد.
if Entry.objects.filter(headline="Test"):
print("There is at least one Entry with the headline Test")نکته: اگر تنها کاری که میخواهید انجام دهید این است که ببینید آیا حداقل یک نتیجه وجود دارد، کار فوق را انجام ندهید و بجاش از exists() استفاده کنید.
Pickling QuerySets
اگر شما به یک QuerySet یک pickle بزنید، این کار باعث می شود که تمامی نتایج قبل از pickleشدن درون مموری کش شوند. picklingمعمولا به عنوان مقدماتی برای caching استفاده می شود و هنگامی که QuerySet کش شده مجدد بارگذاری می شود، میخواهید که نتایج از قابل حاضر و آماده استفاده باشند (خواندن از پایگاه داده زمان می برد و هدف از cachingرا شکست می دهد.) به این معنی است که زمانی که شما QuerySet را از pickle در می آورید، به جای نتایجی که در حال حاضر در پایگاه داده وجود دارد، دارای نتایج زمان pickle شدن شان هستند.
اگر شما تنها نیاز دارید اطلاعات ضروری را pickleکنید تا QuerySet را مجدد از روی پایگاه داده در زمانی بعداً بسازید، ویژگی کوئری از QuerySet را pickleکنید.
>>> import pickle >>> query = pickle.loads(s) # Assuming 's' is the pickled string. >>> qs = MyModel.objects.all() >>> qs.query = query
برای خوانا بودن کوئری ها از Lazy Evaluation استفاده کنید
در کوئری های پیچیده، سعی کنید تا از زنجیره ای کردن بیش از حد در تعداد خط کم پرهیز کنید:

قشنگ نیست! برای رهایی از این نازیبایی، کافیست از ویژگی Lazy evaluation از جنگو کوئری استفاده کنیم تا کد های ORMخودمان را تمیز نگه داریم.
با استفاده از lazy evaluation، منظورمان این است که Django ORM فراخوانی SQL ها را تا زمانی که حقیقتا به آن نیاز نباشد، انجام نمی دهد.ما می توانیم توابع و متدهای ORM را هر طور که میخواهیم زنجیره کنیم، و تا زمانی که نخواهیم نتیجه را مرور کنیم، جنگو پایگاه داده را لمس نخواهد کرد. برای افزایش خوانایی، به جای آنکه کوئری و زنجیره را در یک خط بنویسیم، بهتر است در چند خط بنوییسیم تا خوانایی را بهبود دهیم تا منجر به نگهداری آسانتر در بعدها شویم.
همان تصویر فوق را در زیر مشاهده کنید:
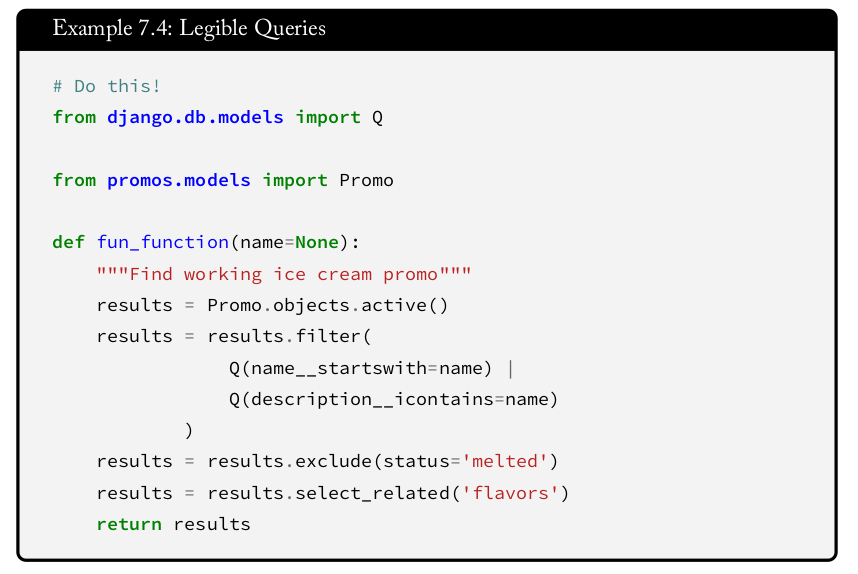
گرفتن objectهای مورد نظر با استفاده از filterها
QuerySet ای که با all() فراخوانی می شود، تمام objectها را بر می گرداند. گاهی اوقات شما نیاز دارید تا تنها زیر مجموعه ای از کل مجموعه object ها را انتخاب کنید.
برای ساخت چنین زیر مجموعه ای، شما روی QuerySet اولیه یک پالایش انجام می دهید و شرط های فیلتر را اعمال می کنید. دو روش رایج برای پالایش کردن QuerySet عبارت است از:
filter(**kwargs)
یک QuerySet جدید شامل objectهایی که با پارامترهای جستجوی داده شده منطبق هستند را بر می گرداند.
- exclude(**kwargs)
یک QuerySet جدید شامل objectهایی که منطبق با پارامتر های جستجوی داده شده نباشند را بر می گرداند.
پارامترهای جستجو (**kwargs) باید در فرمت تعریف شده زیر باشند.
برای مثال تمامی مدخل های بلاگ که از سال ۲۰۰۶ هستند:
Entry.objects.filter(pub_date__year=2006)
فیلتر های زنجیره ای:
نتیجه یک QuerySet خودش یک QuerySet می باشد پس می توان چند تای آنها را با همدیگر پالایش کرد:
>>> Entry.objects.filter( ... headline__startswith='What' ... ).exclude( ... pub_date__gte=datetime.date.today() ... ).filter( ... pub_date__gte=datetime.date(2005, 1, 30) ... )
کد بالا ابتدا تمامی Entry های دیتابیس را بر می گرداند، یک فیلتر به آن اضافه می کند، سپس یک exclude و سپس یک filterدیگر. نتیجه نهایی یک QuerySet است که شامل تمامی Entry هایی است که با سر تیتری شروع می شوند که دارای «What» است و از ۳۰ ژانویه ۲۰۰۵ تا امروز منتشر شده اند.
QuerySet های فیلتر شده، منحصر بفرد هستند
هر زمانی که شما یک QuerySet را پالایش می کنید، شما یک QuerySet جدید میگیرید که هیچ اشتراکی با QuerySet قبلی ندارد. هر پالایش یک QuerySet مجزا و مستقل می سازد که می تواند ذخیره شود، استفاده شود یا استفاده مجدد شود.
مثال:
>>> q1 = Entry.objects.filter(headline__startswith="What") >>> q2 = q1.exclude(pub_date__gte=datetime.date.today()) >>> q3 = q1.filter(pub_date__gte=datetime.date.today())
سه QuerySet فوق مجزا از هم هستند. QuerySet اولی کوئری ست مبنایی می باشد که شامل تمام Entry هایی هست که سر تیتر آنها با What شروع شده است. دومی زیر مجموعه ای از اولی است با معیار و ضابطه جدیدی که رکورد هایی که pub_date آنها امروز یا آینده است را خارج می کند. سومی زیر مجموعه ای از اولی است که فقط رکورد هایی را انتخاب می کند که pub_dateآنها امروز یا آینده می باشد. کوئری ست مبنایی اولیه ( QuerySet (q1))توسط فرآیند پالایش هیچ آسیبی ندیده است.
QuerySet ها تنبل (lazy) هستند
کوئری ست ها lazyهستند، عمل ساخت یک کوئری ست شامل هیچ فعالیت دیتابیسی نمی شود.شما می توانید تمامی فیلتر ها را در تمامی روز کنار هم پشته کنید، و جنگو در عمل زمانی کوئری را اجرا می کند که کوئری ست ارزیابی شود. به مثال زیر توجه نمایید:
>>> q = Entry.objects.filter(headline__startswith="What") >>> q = q.filter(pub_date__lte=datetime.date.today()) >>> q = q.exclude(body_text__icontains="food") >>> print(q)
گرچه به نظر می رسد سه بازدید (hitکردن DB) از دیتابیس اینجا رخ می دهد، اما در حقیقت فقط یک مرتبه پایگاه داده را می بیند (hit کردن DB) و آن در خط آخر و بهنگام print است. بطور معمول نتیجه یک کوئری ست از سمت DBواکشی نمی شود مگر تا زمانی که آنها را بخواهیم. زمانی که شما بخواهید، کوئری ست با دسترسی به پایگاه داده ارزیابی می شود. برای اینکه بدانید کوئری ست چه زمان هایی ارزیابی می شود، بخش ارزیابی QuerySet را در ببخش بالاتر مطالعه کنید.
گرفتن یک Object به تنهایی با استفاده از get()
filter() در هر صورت به شما یک QuerySet بر می گرداند، حتی اگر تنهای یک objectبا filter همخوانی داشته باشد.
اگر شما می دانید که فقط یک Objectبا شرایط تان مطابقت دارد، می توانید از get() استفاده کنید.
>>> one_entry = Entry.objects.get(pk=1)
فقط توجه داشته باشید، یک تفاوت بین get() و filter() وجود دارد و آن هم [0] می باشد، داگر هیچ نتیجه ای با کوئری شما همخوانی نداشته باشد، get()یک exceptionاز نوع DoesNotExist بلند می کند. این exception صفتی از کلاس مدلی می باشد که کوئری روی آن اجرا شده، برای مثال فوق اگر entryبا pk=1وجود نداشته باشد، جنگو Entry.DoesNotExist را بلند خواهد کرد.
نکته: برای Single Objectها از get_object_or_404() بجای get()استفاده کنید. فقط در viewها از get_object_or_404() استفاده نمایید.
متد های دیگر QuerySet
در اغلب موارد بهنگام جستجو روی Object ها از متد های all(), get(), filter() و exclude() استفاده می کنیم، در ادامه به چند متد دیگر از کوئری ست پرداخته ایم:
محدود کردن (limit) کوئری ست ها
از سینتکس برش دادن آرایه ها در پایتون، می توان برای محدود سازی کوئری ست ها به تعداد مشخصی نتیجه استفاده کرد. مشابه با عبارت های LIMIT و OFFSET در SQL .
برای مثال، کد زیر ۵ تا object اول را باز میگرداند:
>>> Entry.objects.all()[:5]
کد زیر object های ۶ تا ۱۰ را بر میگرداند:
>>> Entry.objects.all()[5:10]
نکته : ایندکس دادن منفی برای کوئری ست ها پشتیبانی نمی شود.(Entry.objects.all()[-1])
به طور معمول، برش دادن کوئری ست، یک کوئری ست بر میگرداند و کوئری را ارزیابی نمی کند.
اگر قصد دارید فقط یک Object را بگیرید، بجای استفاده از یک برش، از ایندکس استفاده کنید:
>>> Entry.objects.order_by('headline')[0]Field lookups روی کوئری ست ها
از Field lookups¶ برای استفاده از عبارت WHERE موجود در SQL برای کوئری ست ها استفاده می کنیم. آرگومان پایه برای Field Lookupd به صورت فرم field__lookuptype=value می باشد.
>>> Entry.objects.filter(pub_date__lte='2006-01-01')
که به صورت SQL ای می شود:
SELECT * FROM blog_entry WHERE pub_date <= '2006-01-01';
فیلد مشخص شده در Lookup باید نام فیلد مدل باشد. فقط یک استثنا داریم و اون هم برای کلید خارجی (ForeignKey) می باشد که شما می توانید ماک فیلد را همراه با پسوند _id بیاورید:
>>> Entry.objects.filter(blog_id=4)
exact
به مثال زیر توجه کنید:
>>> Entry.objects.get(headline__exact="Cat bites dog")
مثال فوق برابر است با :
SELECT ... WHERE headline = 'Cat bites dog';
مانند exact می باشد منتهی بدون درنظر گرفتن بزرگی و کوچکی حروف
جستجو هایی که شامل relation ها نیز می شوند
جنگو طبق روال کار ما رو ساده می کنه، اینجا نیز کار ما رو با JOIN خودکاری که میزنه راحت می کنه 🙂
برای پوشش دادن یک RelationShip از اسم فیلد، فیلد مرتبط با مدل استفاده کنید که با دو تا under score از هم جدا شده اند. این کار را تا زمان رسیدن به فیلد مورد نظر خ.ودتون ادامه بدهید. (با مثال بهتر متوجه میشیم)
مثال زیر تمامی Entry های مرتبط با یک Blog که name آن ‘Beatles Blog’ است را می آورد.
>>> Entry.objects.filter(blog__name='Beatles Blog')
مثال زیر تمامی بلاگ هایی را می آورد که حداقل یک Entry با headline شامل ‘Lenon’ دارند را می آورد:
>>> Blog.objects.filter(entry__headline__contains='Lennon')
فیلتر روی رابطه های یک به چند یا چند به چند (ForeighKey and ManyToManyField) در جنگو
زمانی که داریم یک objectرا روی یک ManyToManyField یا یک ForeignKey فیلتر می کنیم، دو حالت چینش متفاوت وجود دارد.
ابتدا یک رابطه را در نظر می گیریم، رابطه ی Blog/Entry از فرضیات اول این مقاله آموزشی رو در نظر بگیرید. رابطه Blog به Entry یک رابطه ی یک به چند می باشد.
- ما میخواهیم بلاگ هایی را بدست بیاوریم که یک entry دارند که هم سر تیتر (headline) آن با «lenon»شروع می شود و هم در سال ۲۰۰۸ منتشر شده است.
- یا اینکه ما بلاگ هایی را می خواهیم که هم دارای entry هستند که سرتیتر آن با «lenon» می شود و همچنین entryکه در سال ۲۰۰۸ منتشر شده باشد.
در نتیجه چندین entry داریم که با یک Blogرابطه دارند. دو کوئری بالا متفاوت خواهند بود، به طور خلاصه :
- کوئری اول بلاگ هایی را می خواهد که دارای مدخل هایی باشد که آن مدخل سرتیترش با «lenon» شروع شده باشد و همچنین اون مدخل در سال ۲۰۰۸ منتشر شده باشد.
- کوئری دوم بلاگ هایی را می خواهد که هم دارای مدخلی باشند که سرتیتر آن با «lenon» شروع شده باشد و هم مدخلی که منتشر شده در سال ۲۰۰۸ باشد.
کوئری اول به شکل زیر می شود:
Blog.objects.filter(entry__headline__contains='Lennon', entry__pub_date__year=2008)
کوئری دوم به شکل زیر می شود:
Blog.objects.filter(entry__headline__contains='Lennon').filter(entry__pub_date__year=2008)
نکته: برای کوئری های دارای روابط چندگانه رفتار filter که رد بالا توضیح داده شده، به طور مشابه برای exclude پیاده سازی نشده است. در عوض، شرایط روی یک فراخوانی exclude به طور تنها ضرورتا روی همان آیتم اشاره نمی کند. برای مثال، کوئری ذیل، بلاگ هایی که شامل جفت entryهایی با سر تیتیر «lenon » و entry های منتشر شده در سال ۲۰۰۸ هستند را exclude می کند
Blog.objects.exclude(
entry__headline__contains='Lennon',
entry__pub_date__year=2008,
)با این حال، برخلاف رفتار بهنگام استفاده از filter ، بلاگ ها را محدود به entry هایی با برآورده شدن هر دو شرط نمی کند. برای انجام این کار، یعنی انتخاب همه بلاگ هایی که شامل entryهایی با سر تیتر «lenon» و سال منتشر ۲۰۰۸ نباشند، شما نیاز دارید تا دو کوئری انجام دهید:
Blog.objects.exclude(
entry__in=Entry.objects.filter(
headline__contains='Lennon',
pub_date__year=2008,
),
)خب ادامه ی مطالب رو در قسمت بعدی در خدمتتون هستم 🙂